









CopyRight©2021 139GAME.COM.CN All Right Reserved
智谱GLM-4-9B模型:幻觉率仅1.3%,全球大模型评测拔得头筹
时间:2025-01-10 16:52:48
编辑:001资源网
近日,在人工智能这个充满活力又不断面临挑战的领域内,大语言模型的“幻觉问题”犹如一座大山,一直横亘在业界面前,成为了一个极为关键的难题。
测试数据显示,在参与评估的85个大语言模型中,GLM-4-9B以98.7%的事实一致性率和100%的回答率摘得桂冠。特别值得关注的是,该模型的幻觉率仅为1.3%,这一成绩不仅位居榜首,更是超越了行业巨头OpenAI的GPT系列和Google的Gemini系列模型。
这一突破性成果标志着中国大语言模型在降低“幻觉率”方面取得重要进展,为提升AI应用的可靠性和准确性带来新的可能。这不仅体现了智谱AI在模型研发上的技术实力,也为全球AI领域树立了新的标杆。
在当前AI技术竞争日益激烈的背景下,GLM-4-9B模型的出色表现无疑将为智谱AI赢得更多关注,同时也为中国AI企业在国际舞台上赢得了更多话语权。
智谱AI公开CogVideoX-5B视频生成模型,RTX 3060显卡亦能驾驭
8月28日消息,智谱AI宣布开源其升级版视频生成模型CogVideoX-5B,相较于早前的CogVideoX-2B,此次发布的模型在视频生成的质量与视觉表现上实现了显著提升,标志着AI视频生成技术的又一重要进步,为内容创作者和研究人员提供了更加强大的工具,进一步拓宽了AI技术在多媒体内容创作领域的应用前景。

官方表示大幅度优化了模型的推理性能,推理门槛大幅降低,可以在 GTX 1080Ti 等早期显卡运行 CogVideoX-2B ,在 RTX 3060 等桌面端“甜品卡”运行 CogVideoX-5B 模型。
CogVideoX 是一个大规模 DiT(diffusion transformer)模型,用于文本生成视频任务,主要采用了以下技术:
3D causal VAE:通过压缩视频数据到 latent space,并在时间维度上进行解码来实现高效的视频重建。
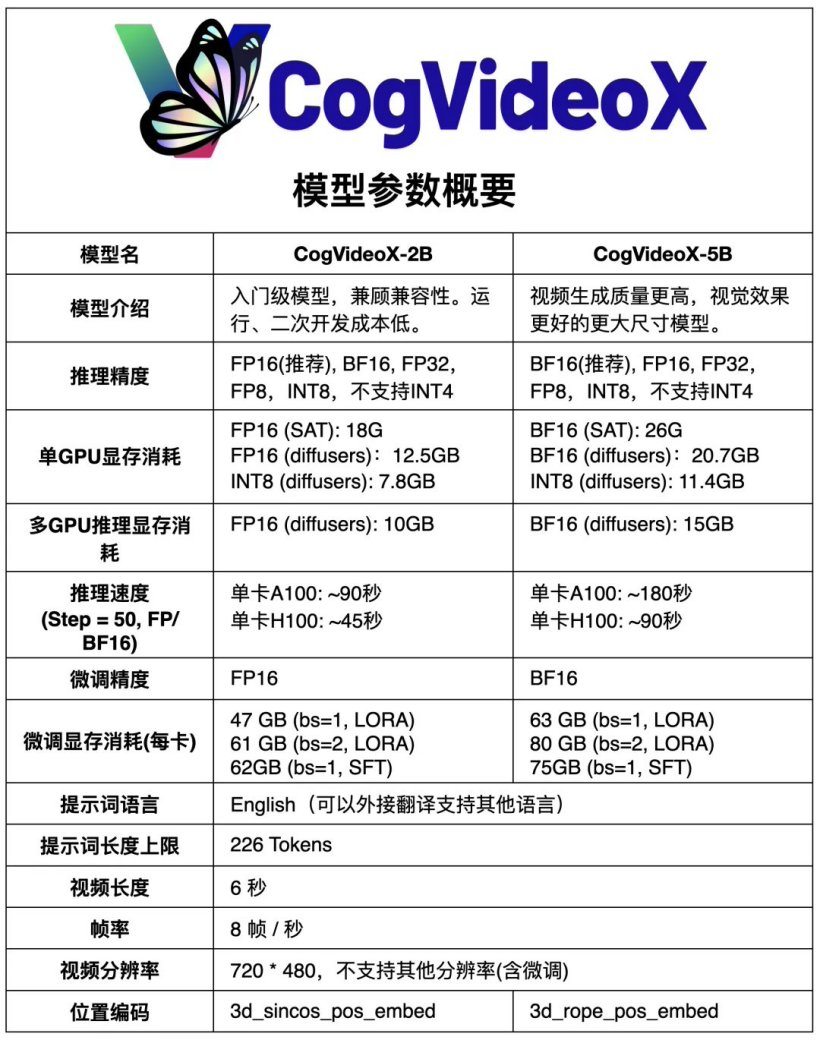
专家 Transformer:将文本 embedding 和视频 embedding 相结合,使用 3D-RoPE 作为位置编码,采用专家自适应层归一化处理两个模态的数据,以及使用 3D 全注意力机制来进行时空联合建模。